凤凰彩票app2026世界杯最新下载 刚刚, 何恺明ResNet、YOLO获时候检修奖! CVPR 2026奖项出炉


机器之机杼剪部
北京时候周五晚间,CVPR 2026 认真公布了本年的获奖论文,很多咱们熟知的霸术获取了本年的奖项。
CVPR 是贪图机视觉与步地识别领域公认的寰球顶级学术会议,亦然臆想寰球高校、科研机构及学者学术水平的迫切标识。在谷歌学术(Google Scholar)通盘领域科学期刊 / 会议的影响力排行中,CVPR 位列第二名,仅次于《Nature》。
在霸术方进取,CVPR 掩盖的范围已特别庸俗,包含东说念主工智能、具身智能、自动驾驶、多模态学习、大谈话模子、AR/VR 等浩荡前沿且热点的目的。
本年的大会于 6 月 3-7 日在好意思国科罗拉多州丹佛市举行。机器之心来到了大会现场,并发来了现场报说念。
CVPR 2026 数据分析
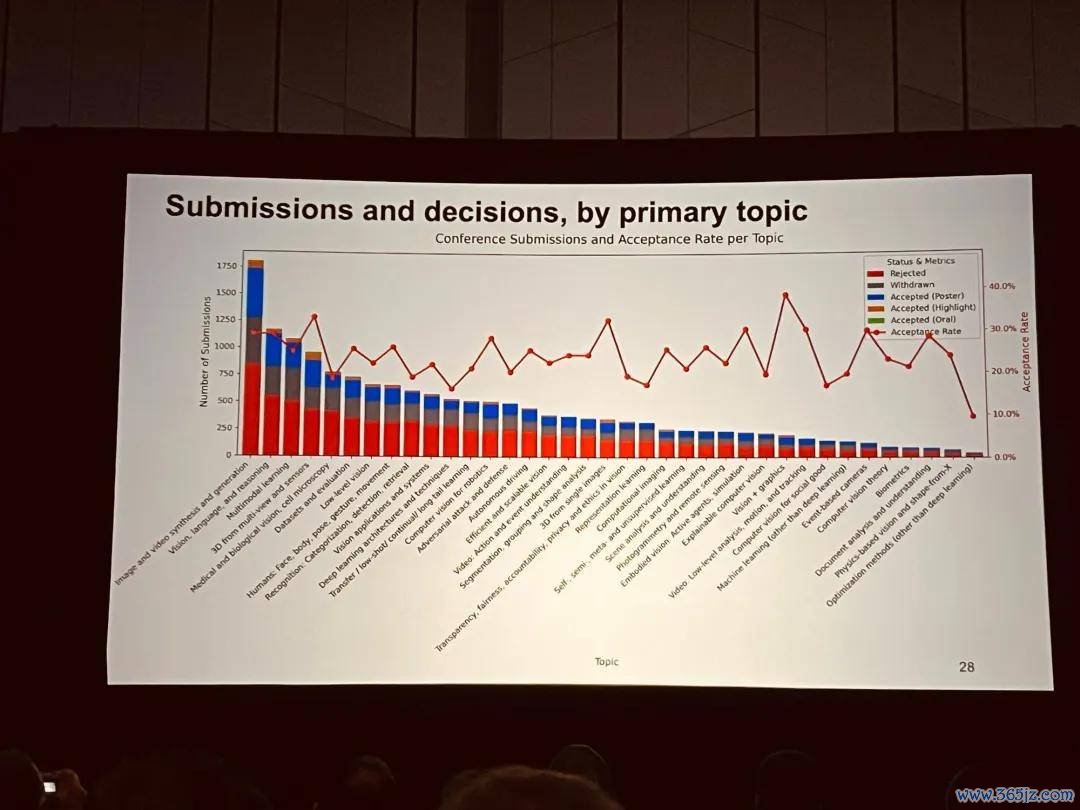
CVPR 2026 共收到 16092 篇投稿,其中 4071 篇被大会接收(highlights 141 篇;poster 3352 篇),接收率 25.3%。今天在大会受奖仪式上又公布了更多醒目的数据分析。不错看到,本年的论文数目又改动高,比客岁增长了 23.71%。
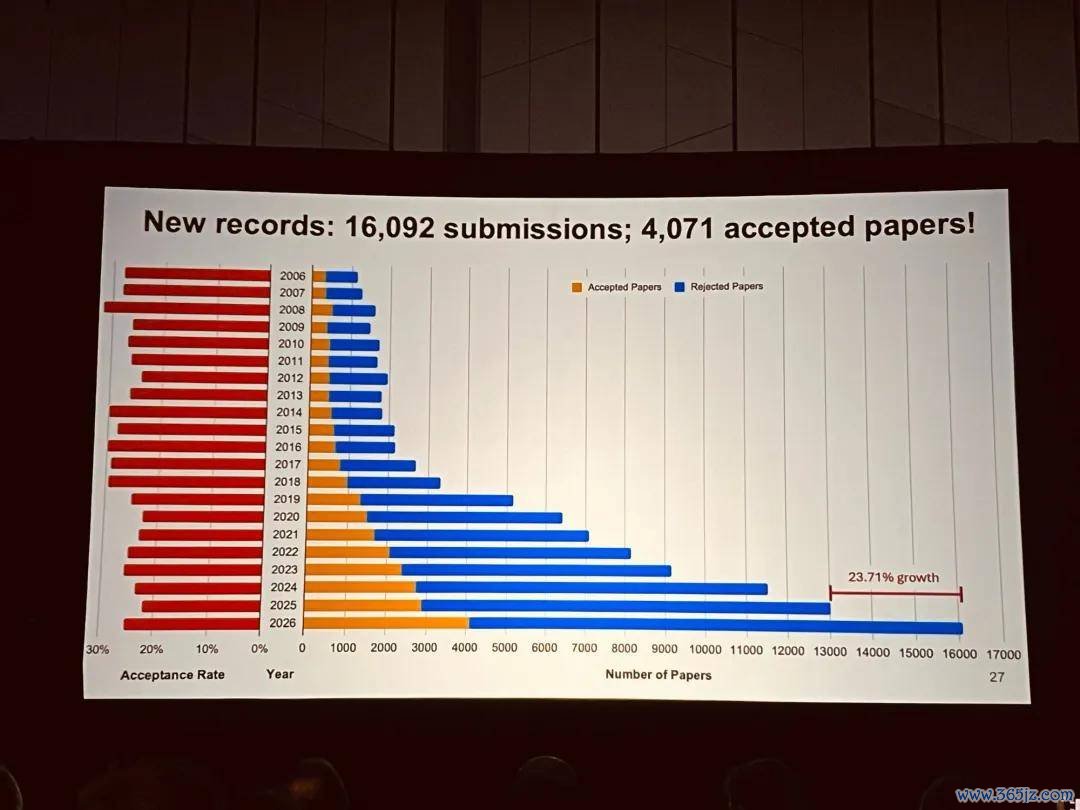
积年论文提交、审稿东说念主、领域主席数目如下:

CVPR 2026 论文作家、审稿东说念主开端地:
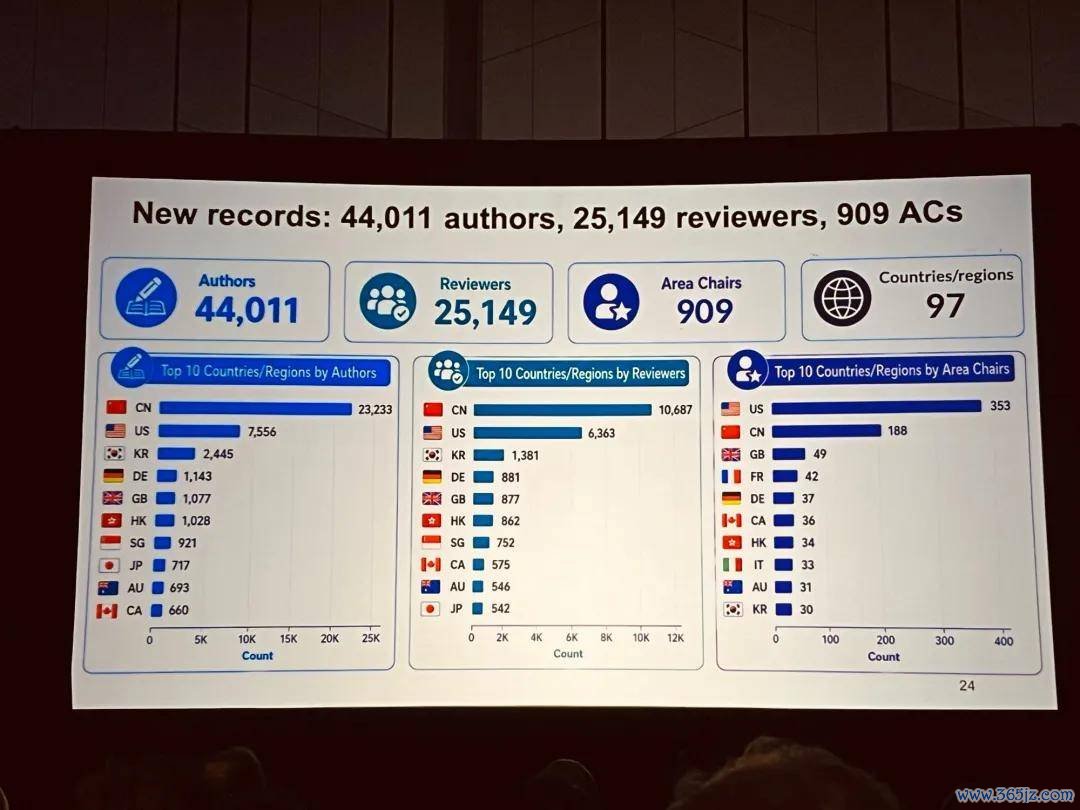
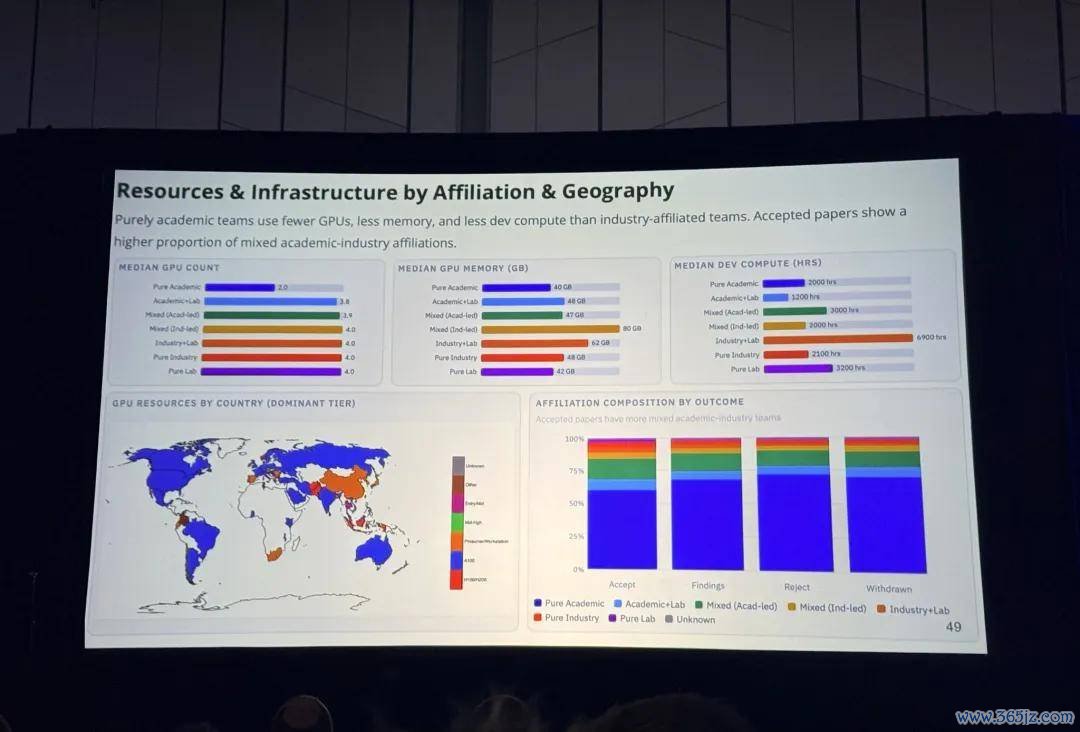
底下是愈加兴味兴味的一些信息。如今是 AI 期间,东说念主们特别护理算力,CVPR 2026 也稳健潮水展示了社区入网算资源的使用情况,从 GPU 数目、内存占用,到拓荒贪图和团队的附庸干系:
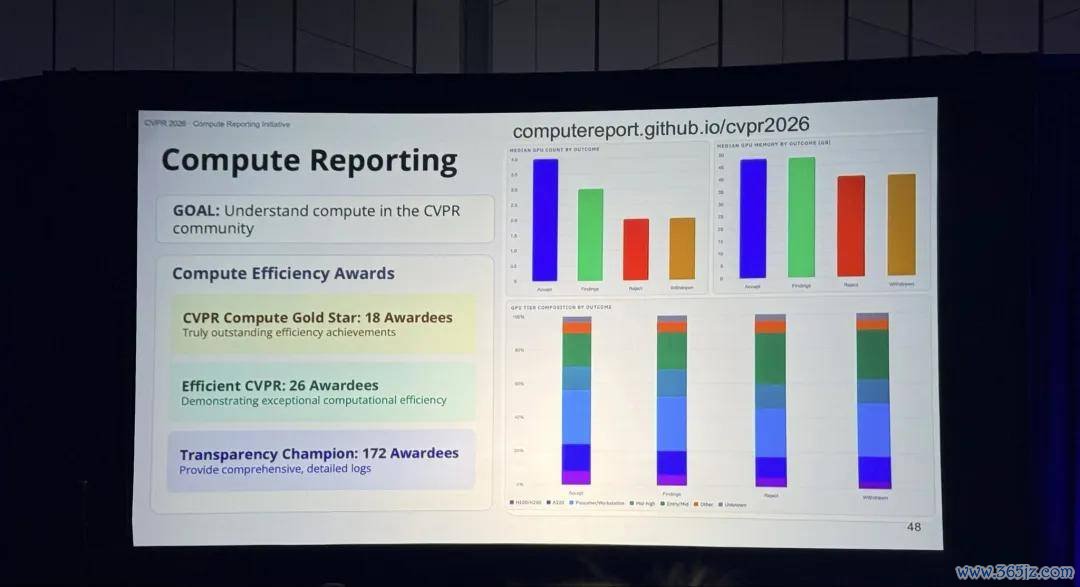
可见现时作念贪图机视觉霸术是东说念主均 4 块 GPU,40GB 显存起步,工业界的算力销耗一骑绝尘:
接下来即是万众期待的奖项了。
本年最好论文奖项共有 74 篇论文入围,其中 15 篇插足决赛圈。最终,有 5 篇获奖拿到奖项。奖项包括:
1 篇最好论文奖
2 篇最好论文奖提名
1 篇最勤学生论文
1 篇最勤学生论文奖提名
最好论文

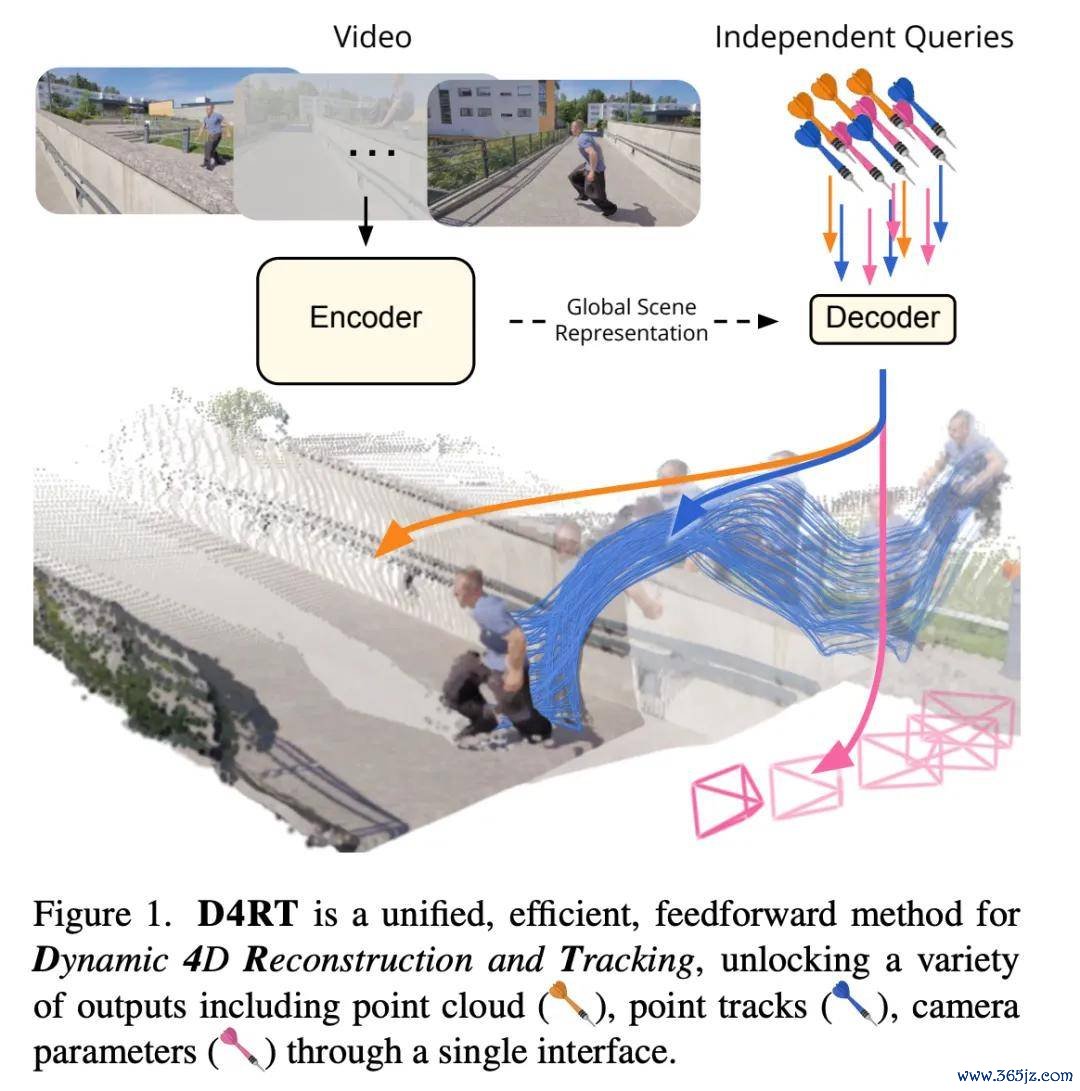
获奖论文:Effciently Reconstructing Dynamic Scenes One D4RT at a Time
机构:谷歌 DeepMind、伦敦大学学院、牛津大学
动态场景的 4D 重建很难,现存圭表要么把任务拆成多个模块分歧处理(慢、复杂),要么无法处理动态区域的对应干系,要么两者皆有。
作家提倡将范式从「碎屑化的逐帧解码」转机为「高效的按需查询」,并由此引入 D4RT。如图 1 所示,模子先用编码器把整段视频压缩成一个全局场景暗意,再用一个轻量解码器按需恢复「视频中某个点在某个本领的 3D 位置是什么」—— 深度图、点云、点轨迹、相机参数,沿途通过团结套查询接口输出。
在动态 4D 重建与跟踪任务上,该模子达到新的 SOTA,速率和精度均优于现存圭表,并支执对视频沿途像素进行繁荣合座重建。
CVPR 2026 最好论文的第一作家是 DeepMind 资深霸术科学家 Chuhan Zhang(张楚晗),她此前在牛津大学几何霸术组 (VGG)获取博士学位,导师为 Andrew Zisserman。

张楚晗的霸术目的涵盖视频涌现、动态 3D 场景重建以及生成模子的自动评估经由。
最好论文奖提名 (2 篇)

获奖论文 1:SAM 3D: 3Dfy Anything in Images
机构:Meta 超等智能推行室
贯穿:https://arxiv.org/abs/2511.16624
霸术提倡了一个用于视觉基底 3D 物体重建(Visually Grounded 3D Object Reconstruction)的生成式模子,大要从单张图像中预计出物体的几何结构、纹理和布局。SAM 3D 在当然着实图像中阐扬优异,而这类图像时时存在大宗的遮拦和凌乱场景,K体育(中国)官网入口此时来自尊下文的视觉识别印迹时常证明着更要津的作用。
霸术团队通过一个「东说念主机协同」(Human- and Model-in-the-Loop)的管线达成了这一突破,该管线用于标注物体的时局、纹理和姿态,从而提供了领域空前的视觉基底 3D 重建数据。霸术东说念主员在一个当代化的多阶段教师框架中诈欺这些数据进行学习,该框架将合成数据预教师(Synthetic Pretraining)与着实宇宙对皆(Real-World Alignment)相皆集,从而冲突了 3D 领域的「数据壁垒」。
相较于近期的其他责任,该霸术取得了显赫的升迁 —— 在针对着实宇宙物体和场景的东说念主类偏好测试(Human Preference Tests)中,获取了至少 5:1 的胜率。

获奖论文 2:NitroGen: An Open Foundation Model for Generalist Gaming Agents
机构:英伟达、斯坦福大学、加州理工学院、芝加哥大学和德克萨斯大学奥斯汀分校
贯穿:https://arxiv.org/abs/2601.02427
该霸术的中枢孝敬在于推出了 NitroGen,一个用于通用游戏智能体的视觉 - 算作基底模子(Vision-Action Foundation Model)。该模子在涵盖 1000 多款游戏、觉得 40,000 小时的游戏试玩视频上教师而成。
该霸术融入了三个中枢身分:
1. 一个互联网领域的「视频 - 算作」数据集,该数据集是通过自动从公开的游戏视频中索要玩家算作而构建的;
2. 一个不错评估跨游戏泛化能力的多游戏基准测试环境;
3. 一个通过大领域行径克隆(Behavior Cloning)教师而成的长入视觉 - 算作模子。
NitroGen 在多种不同的游戏领域中都展现出了强劲的能力,包括 3D 算作游戏中的构兵抵拒、2D 平台游戏中的高精度适度,以及才智化生成宇宙中的探索。该模子还能极好地移动至从未见过的全新游戏,相较于重新运转教师的模子,其任务告捷率达成了高达 52% 的相对升迁。
最勤学生论文

获奖论文:Native and Compact Structured Latents for 3D Generation
机构:清华大学、微软霸术院、USTC、微软 AI
论文贯穿:https://cvpr.thecvf.com/virtual/2026/poster/37074
近期,三维生成建模领域取得了显赫进展,生成着实感大幅升迁,但现存暗意圭表仍存在瓶颈,难以捕捉具有复杂拓扑结构和缜密外不雅的三维钞票。
本文提倡一种圭表,凤凰彩票app2026世界杯最新下载从原生三维数据中学习结构化的潜在暗意,以应酬这一挑战。其中枢是一种名为 O-Voxel 的新式疏淡体素结构 —— 一种同期编码几何与外不雅的全向体素暗意。O-Voxel 大要稳健地建模任性拓扑,包括怒放、非流形及全闭塞名义,同期捕捉纹理情态除外的丰富名义属性,举例基于物理的渲染参数。
基于 O-Voxel,作家联想了疏淡压缩变分自编码器,达成了高空间压缩率和紧凑的潜在空间。他们诈欺万般化的公开三维钞票数据集,教师了包含 40 亿参数的大领域流匹配模子用于三维生成。尽管领域弘远,推理过程依然高效。同期,所生成钞票的几何与材质质料远超现存模子。
最勤学生论文奖提名

获奖论文:ChordEdit: One-Step Low-Energy Transport for Image Editing
机构:广东工业大学、惠州学院、深圳大学、北京大学
一步式文本生成图像(T2I)模子的出现,带来了前所未有的生成速率。关联词,将这类模子用于文本带领的图像裁剪,仍然濒临严重抑遏:要是强行把现存的免教师裁剪圭表压缩到单步推理中,时常会失败。这种失败主要阐扬为物体严重变形,以及非裁剪区域一致性的彰着丢失。其根源在于,平直在模子的结构化场上作念朴素的向量运算,会产生高能量、剧烈抖动的轨迹。
为了惩办这一问题,霸术者提倡了 ChordEdit。这是一种与模子无关、无需教师、也无需反演的圭表,大要达成高保的确一步式图像裁剪。他们将图像裁剪再行表述为一个传输问题:在由源文本教唆词和沟通文本教唆词所界说的源漫步与沟通漫步之间进行传输。
基于动态最优传输表面,霸术者推导出一种有原则的拙劣量适度政策。该政策大要得到更平滑、方差更低的裁剪场,况且自然愈加矜重,使得这一裁剪场不错通过一次较大的积分步长完成遍历。
凭借这一有表面撑执、并经过推行考据的圭表,ChordEdit 大要达成快速、轻量且精准的图像裁剪,最终让这类具有挑战性的一步式模子信得过具备及时裁剪能力。
Longuet-Higgins Prize(朗格 - 希金斯奖)
Longuet-Higgins Prize 是 CVPR 上颁发的「时候检修奖」,赏赐十年前发表且对贪图机视觉领域产生久了影响的 CVPR 论文,以表面化学家与领悟科学家 H. Christopher Longuet-Higgins 定名。
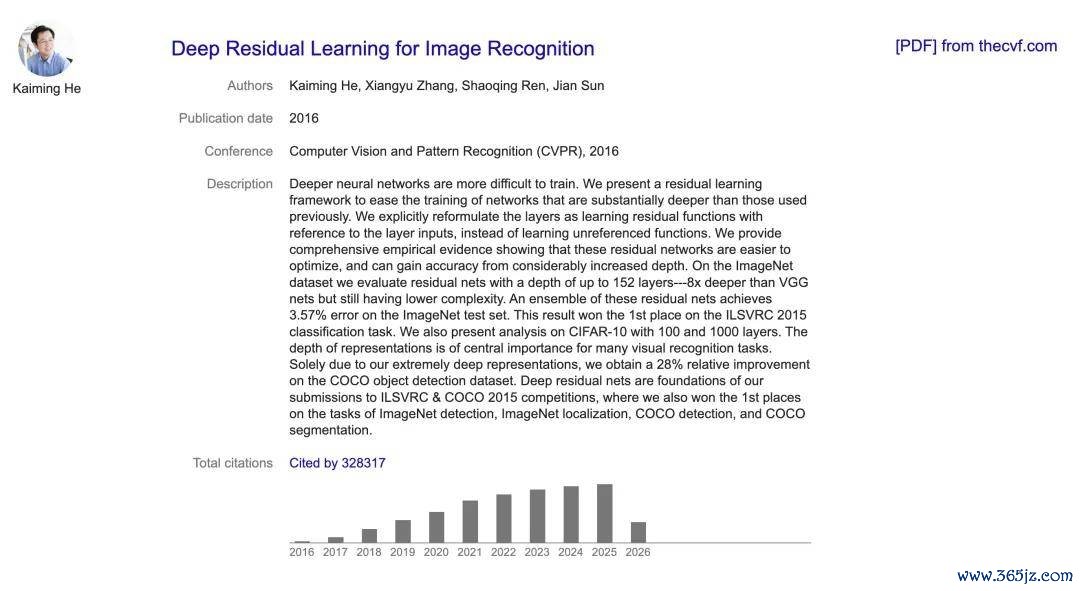
本年度共有两篇论文获奖。其中一篇是 ResNet 的原始论文《Deep Residual Learning for Image Recognition》,由何恺明、张祥雨、任少卿和孙剑于 2015 年撰写,2016 年发表于 CVPR。

ResNet 论文之是以经典,中枢在于它惩办了深层神经收集教师的中枢穷困。它用残差勾通惩办了收集层数增加时信息传递失真、梯度消失 / 爆炸的问题,其想路是让每一层同期接收上一层处理收尾和原始输入并重复后传递,让深度神经收集信得过可教师。ResNet 由此成为深度学习的基础架构:十年来简直通盘主流深度收集架构都以残差勾通为默许成就,掩盖视觉领域 CNN、NLP 领域 Transformer、大谈话模子等各样模子。
现时,该论文的被引量仍是跨越 32 万。
另一篇获奖论文是 YOLO v1 的原始论文,发表于 CVPR 2016,作家是 Joseph Redmon 等东说念主。

在 YOLO 之前,检测主流是 R-CNN 系列 —— 先找候选框(Region Proposal),再对每个框分类。这好比先让助理把像片里通盘可能有东说念主物的区域圈出来,你再逐一辨别。
YOLO 的想路是:整张图只看一次(You Only Look Once),平直输出「何处有什么」。它把检测再行界说为一个端到端的转头问题:输入图像,平直输出领域框坐标和类别概率。
YOLO v1 在 Titan X 上跑到 45 FPS,Fast YOLO 版块以至 155 FPS。这是第一次让「及时检测」信得过可用。这种极简优雅的范式平直催生了 SSD、RetinaNet 及后续通盘这个词 YOLO 眷属,于今仍是工业界部署的主流蹊径。
现时,该论文的被引量接近8万次。

年青学者奖
这是贪图机视觉领域面向后生学者的一个迫切功绩奖项。
它主要奖励博士毕业 7 年以内,仍是在贪图机视觉领域作念出凸起霸术孝敬的年青霸术者。这个奖的含金量在于,它看的不是某一篇论文,而是一个后生学者仍是变成的霸术目的、代表性恶果和领域影响力。
本年获奖者是卡内基梅隆大学副解说 Deepak Pathak 和麻省理工副解说 Vincent Sitzmann。

Deepak Pathak 霸术聚焦东说念主工智能,主要横跨贪图机视觉、机器学习和机器东说念主三大目的,护理机器东说念主如安在着实宇宙中学习、感知和行动。
Vincent Sitzmann 霸术中枢是让机器大要像东说念主同样涌现和模拟宇宙,代表性目的包括神经场景暗意(neural scene representations)、3D 视觉、生成模子、视频建模、机器东说念主感知与贪图等。
Thomas S. Huang 记念奖
Thomas S. Huang 记念奖旨在赏赐在贪图机视觉领域的霸术、素养 / 指导和做事方面号称典范的霸术东说念主员(博士毕业至少 7 年),该奖项是为了记念已故华侨贪图机科学家黄煦涛而设立的。

本年的获奖者是康奈尔大学的贪图机科学解说 Noah Snavely凤凰彩票app2026世界杯最新下载,他的霸术目的是贪图机视觉和图形学。